
Abstract
- A Multi-core Chip with thousands of tiny cores
Optimised for Parallel Computing
Look at the number of cores it has!
Game rendering
So many cores allows us to perform a ton of linear algebra calculation for game graphic rendering.
Great for training AI
AI training involves a ton of Matrix Multiplication on dataset which can be done independently.
Hard to program
That is why we have Nvidia’s CUDA Toolkit which utilises GPU’s parallel computing for general purpose computing.
Streaming Multiprocessor
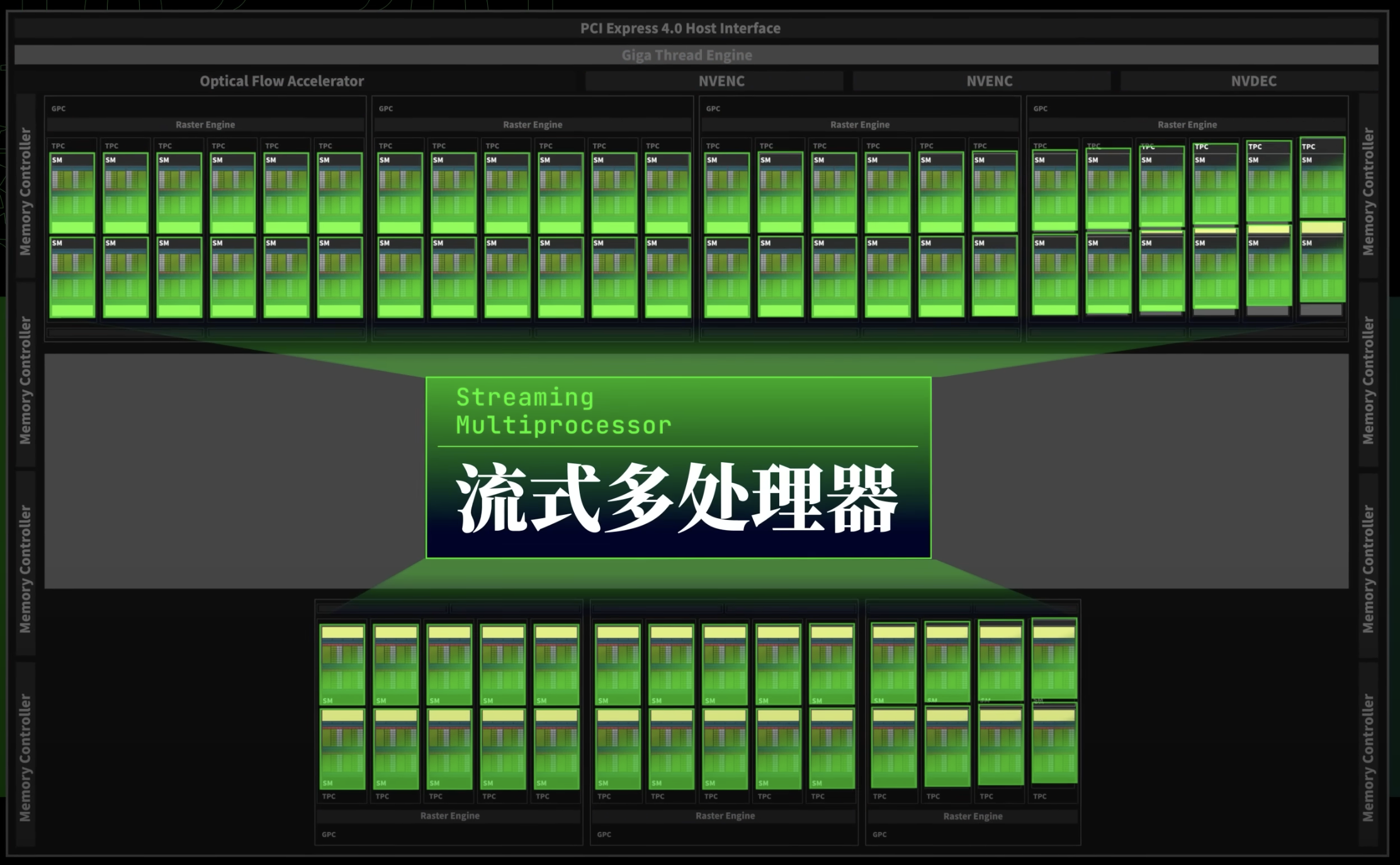
- A physical unit inside the GPU. Each SM has its own register, ALU and share memory and warp schedulers. Can think of it as a CPU
- An SM can handle multiple blocks at the time as long as there are enough resources available to fit them
CUDA Core
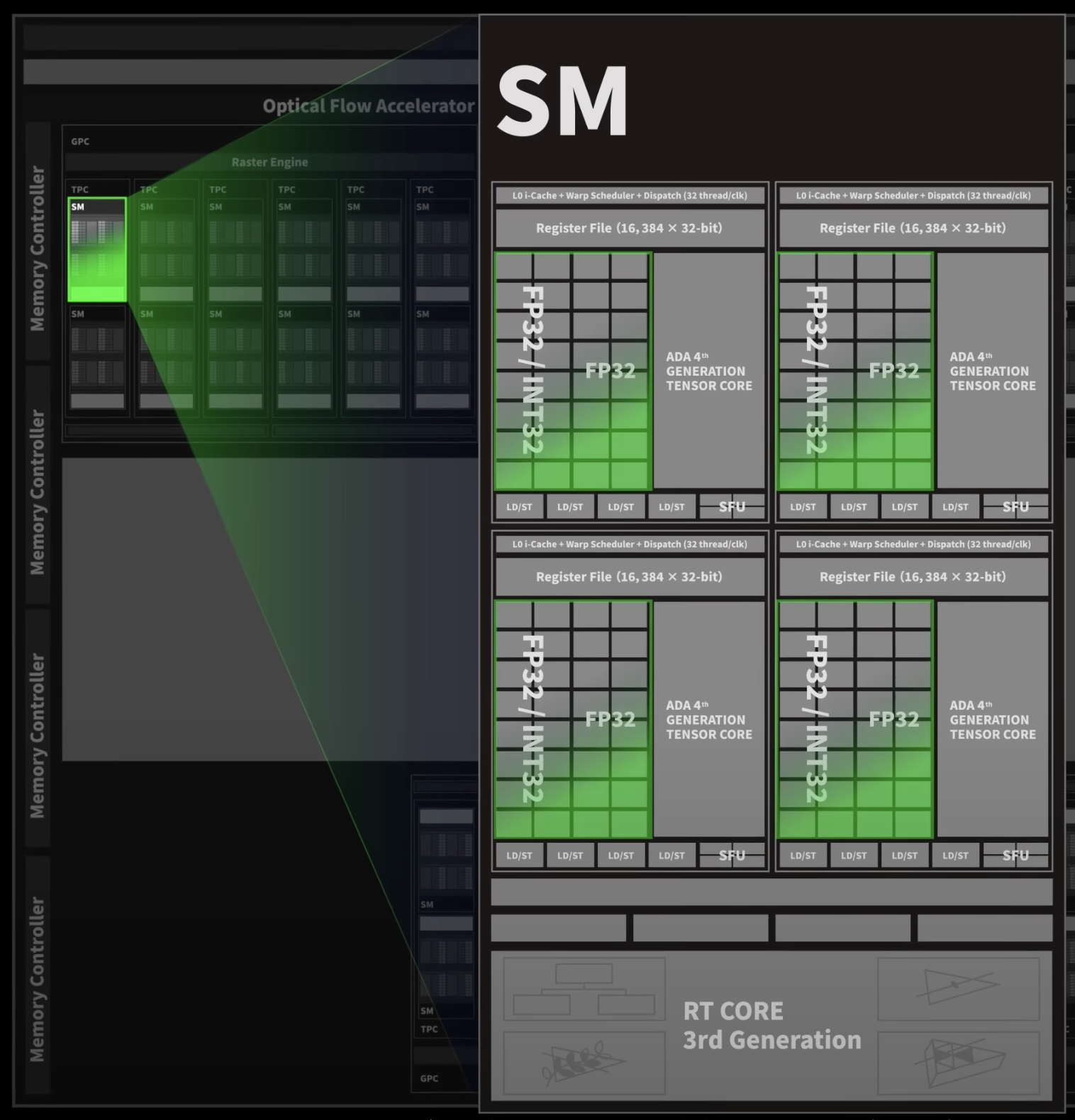
- A CUDA core is mainly responsible for floating-point calculations, but it’s not limited to that, it can also handle integer and logic operations. Or even tensor operations if Tensor Cores are available.
- In short, it’s a general-purpose compute unit inside the GPU that does most of the heavy lifting.
Register access
Each thread (not each core) gets its own set of registers from the SM’s register file. All threads running inside the same SM share that giant register file, but each one gets its own slice of it.
Tensor Core
- A Tensor Core is a specialized math engine inside the GPU, designed to perform matrix multiplications extremely fast. The kind of math AI models rely on.
- CUDA Cores are great at general-purpose arithmetic (like adding, subtracting, or multiplying single numbers), but AI and deep learning deal with big grids of numbers (matrices) instead of single values.
- So in a way, Tensor Cores act like a SIMD engine where one instruction can be applied to a large block of data at once, giving insane compute throughput. They were introduced after the AI boom, specifically to handle neural network math more efficiently.
DLSS
NVIDIA’s AI-based upscaling technology. It renders the game at a lower resolution (like 1440p instead of 4K), then uses a neural network to “fill in” the missing details, so it looks like 4K but runs much faster.
The neural network used by DLSS is trained by NVIDIA (offline in their datacenters) and executed on your GPU’s Tensor Cores during gameplay. These models can be updated through driver or game updates. Tensor Cores are crucial here because DLSS inference involves tons of matrix multiplications, and that’s exactly what Tensor Cores are optimized for.
Wrap Scheduler
- Inside the SM, it is like the teacher deciding which group of 32 students (a wrap) should work next.
- Each warp runs independently. They don’t wait for each other. While one warp might be waiting for data (like memory access), another warp can run to keep the SM busy.
FLOPs of a GPU
Determined by 3 things:
The number of CUDA cores
The clock frequency of each core
How many floating-point operations each core can perform per cycle
What is this one cycle multiple operations black magic?
Some architectures can execute multiple operations in one cycle thanks to the Fused Multiply-Add Instruction.
Importance of FLOPs
In computer graphics, almost everything can be represented using triangles. Rendering those graphics depends on the x, y, z coordinates of each triangle’s vertices, and these coordinates are stored as floating-point numbers.
Since rendering involves tons of floating-point operations, like matrix multiplications, lighting, and transformations. GPUs were designed to handle them efficiently.
Later, people realized that AI computations also involve massive amounts of independent floating-point operations (like multiplying matrices and adding results), which are very similar to what happens in graphics rendering.
So GPUs naturally shine in AI workloads too, because they’re built to perform a huge number of floating-point calculations in parallel, exactly what both graphics and deep learning need.

Comparison with CPU
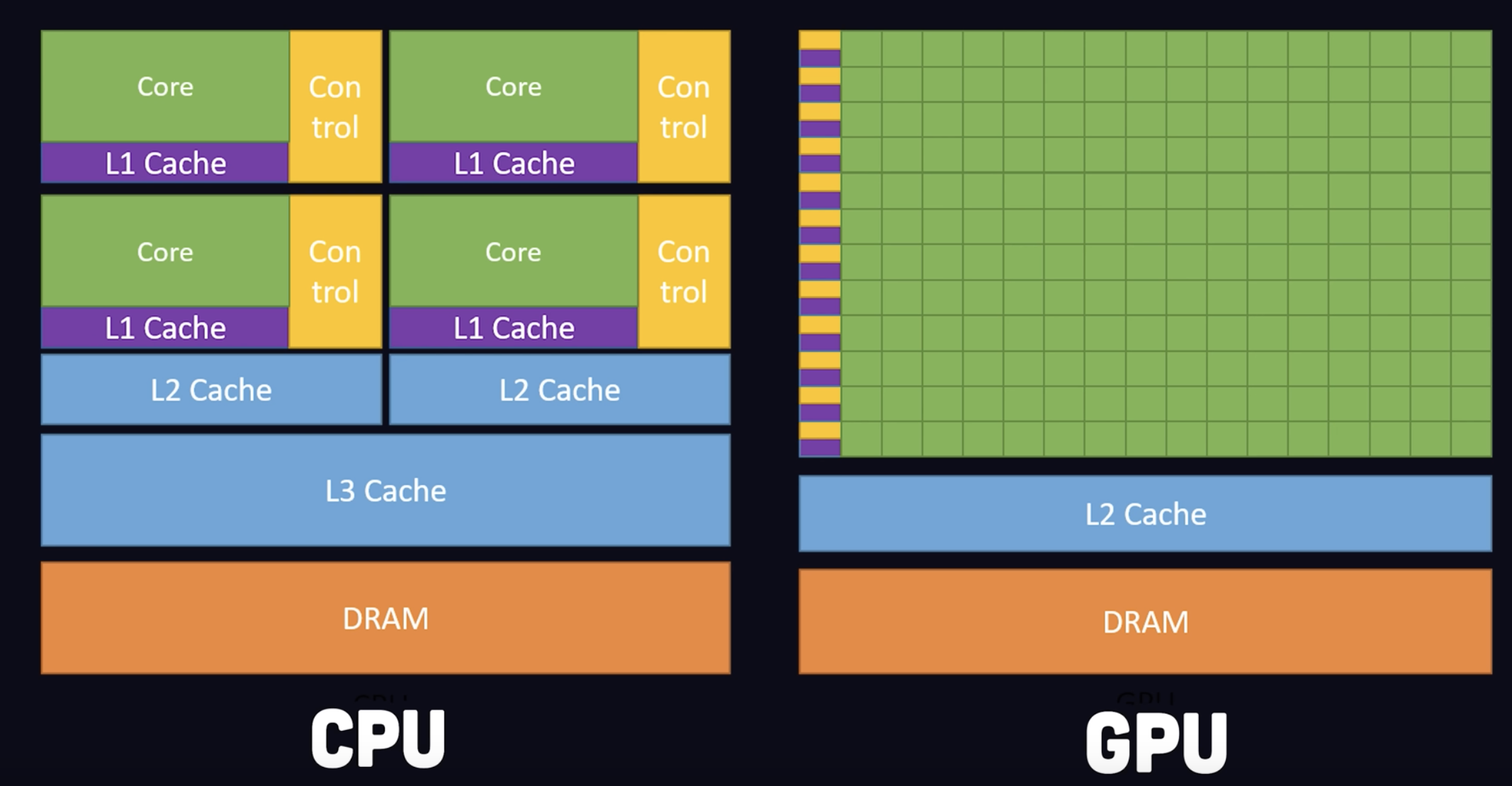
- CPU one core is way more power, and able to handle complication logics like Pipeline Branching and a lot of the real world application needs to run Instruction in a sequential manner
- GPU shines when we need Parallelism (并行性) and the workload doesn’t depend on each other
GPU Access in Virtualised Environments
- Different isolation levels have different capabilities for GPU access
| Isolation Level | GPU Access | Mechanism |
|---|---|---|
| V8 Isolates | No | No system calls, JS/WASM only |
| Containers (runc) | Yes | Direct access to host GPU via mounted device files |
| gVisor | Yes | NVProxy intercepts CUDA calls and proxies to host driver |
| Firecracker | No | Minimal device model, no PCI passthrough |
| QEMU | Yes | PCI passthrough or virtual GPU (vGPU) |
- For GPU partitioning at the hardware level, see Multi-Instance GPU (MIG)
- For GPU scheduling in Kubernetes, see GPU Scheduling